После вчерашней публикации схемы я получил большое количество ругани. Между руганью и критикой грань тонкая, но если приглядеться, её видно. Как правило, ругань отличается от критики тем, что ругающий совершенно не разбирается в теме и пытается выдать тот звон, который он слышал не знаю где, за понимание вопроса.
Шрифт мелкий!
Самая популярная претензия — шрифт мелкий. Благодаря тому, что на схеме ничто ни на что не наползнает, там так много воздуха, что кажется, будто бы есть куча неиспользованного места, и шрифт не настолько велик, насколько мог бы быть. На официальной же схеме настолько тесно, что увеличивать шрифт уже некуда, вот поэтому-то он и кажется большим.
Что бы там не было написано в предыдущем абзаце, шрифт действительно мелкий. Но при этом он точно такой же; даже слегка побольше, чем на сегодняшней официальной схеме.
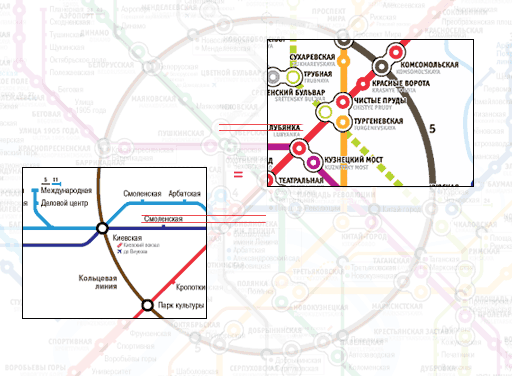
Благодаря тому, что я использую прописные и строчные буквы по назначению, я добился лучшей читаемости. Просто прямоугольные буквы немного лучше растеризуются в пиксели на экране, поэтому на картинке выше кажется, будто текст, набранный заглавными, читается лучше. При печати на бумаге с разрешением даже в 150 DPI преимущество строчных очевидно. Что там говорить, распечатайте любую газетную статью прописными и попробуйте почитать это.
По хорошему, конечно, шрифт для схемы нужно разработать отдельный, открытый и слегка пожирнее.
Несколько человек напомнили мне об удивительной схеме, которая висела пару лет назад (недолго) и сказали, что там тоже был мелкий шрифт и тонкие линии. Шрифт там был в полтора раза меньше, чем у меня, и при этом всё было написано прописными. Линии там тоже были в полтора раза тоньше. Но это всё не важно по сравнению с тем, что там Кольцевая линия не является кольцевой и занимает, при этом, меньше десятой части площади схемы. Привязка схем метро к «реальной географии» только мешает, это стало понятно примерно в 1931 году.
Переход через Театральную
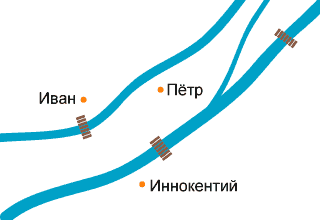
Естественно мгновенно нашёлся человек, сказавший, что с Охотного ряда на Площадь Революции нет перехода, то есть, в нашей терминологии, Иван не может ходить в гости к Иннокентию. Интереснее всего то, что именно этот человек ежедневно переходит с Охотного ряда на Площадь Революции (о чём он сам и написал).
Переход действительно осуществляется через платформу Театральную. Этот факт в моей схеме действительно не отражён. Это сделано мной совершенно сознательно.
Мне представляется эта информация малосущественной и недостойной того, чтобы её отображать на схеме. Ни один из прибывших на станцию Охотный ряд пассажиров, даже зная, что переход на Площадь Революции осуществляется через Театральную, не будет искать указатели «Театральная», чтобы уже оттуда идти на Площадь Революции. Всё равно он будет искать указатель «Площадь Революции», найдёт его, и будет следовать ему. И тот факт, что этот указатель проведёт его через платформу, где ходят поезда Замоскворецкой линии, совершенно не важен для схемы всей системы. Мы ведь не указываем на схеме, где в переходе встречается эскалатор? (Да, я знаю, что вы сейчас скажете — об этом чуть дальше.)
Если считать, что переходом можно называть только прямую трубу, ведущую непосредственно от платформы к платформе, то как в эту концепцию вписываются кросс-платформенные переходы а-ля Китай-город? Там с половинной вероятностью вообще переход (в вышеуказанном смысле) отсутствует, так как одна и та же платформа обслуживает обе пересекающиеся линии.
Всё очень просто. Переходом между станциями называется возможность сменить линию не выходя в город и не платя заново за вход в метро. Всё. Инженерная реализация этой возможности не играет никакой роли. Даже если для перехода нужно подняться на эскалаторе в вестибюль, а потом спуститься на соседнем эскалаторе, переход есть.
На самом деле, переход с Охотного ряда на Площадь Революции на официальной схеме показан весьма удачно. Как будто бы без лишней символики отображает реальность:

Действительно, станции нарисованы в ряд; никто не говорит, что перехода нет, просто видно, что он производится через платформу Театральную. Или не видно? Если честно, если бы моё внимание не обратили на этот момент, я бы этого не заметил. Ну и что, что они тут в ряд расположены, мало ли что у них как расположено на схеме; с реальностью это не имеет ничего общего, взять тот же Китай-город (рядом на том же рисунке).
У меня на схеме станции узла Охотного ряда, кстати, перечислены в точно таком же порядке: Охотный ряд — Театральная — Площадь Революции. Так что, если вдруг схема служит вам просто напоминалкой о порядке этих станций, с этим отлично справляется и моя.
Человек, впервые попавший в Москву, всё равно не догадается, что из расположения платформ в ряд следует «двуэтапность перехода», а уж тем более не сможет мгновенно придумать выходить на Библиотеке имени Ленина.
Александровский сад — Боровицкая
Тонкости устройства узла Библиотеки имени Ленина изобразить просто путём грамотного взаиморасположения платформ авторам официальной схемы уже не удалось:

Хотя при желании могли бы это тоже сделать ненавязчиво, как это, например, сделал автор полинчёванной ещё в сентябре схемы (такое расположение отлично сработает и с кружками).
Кстати, если в случае с Охотным рядом — Площадью Революции эта информация ещё и может быть теоретически полезна для того, чтобы предпочесть перейти на Библиотеке имени Ленина — Арбатской, то в случае с Александровским садом — Боровицкой она вообще никак не влияет на поездку. Если ты едешь со Смоленской-Филёвской на Полянку, ты всё равно пересядешь именно там, выбора нет.
Мусор — на помойку.
Идиотизм дня
Приз за самый идиотский комментарий получает человек, написавший буквально следующее:
Ну и зря нумерацию убрал. А дальтоникам что делать?
Смысла не прибавится и не убавится, если «дальтоников» заменить на «трактористов» или, скажем, «мелиораторов».
Это, вообще, удивительно, как легко человек съел, надо думать, чьё-то предположение о том, что нумерация введена для дальтоников, и даже не задумался о том, а как именно она должна им помочь и в чём.
Latinitsa
Before starting to bitch about how I didn’t put transliterated names of stations on the diagram, you should better ask yourselves how that would indeed help the poor visitor. You know how they remove cars parked incorrectly «to prevent traffic jams»? Do you buy this? Somehow, though, you do buy that nonsense about transliterated names «to help international tourists».
It would make much more sense to first translate the main information lightboxes in the Metro. Go write «Way out» under «Выход в город» and «To the Metro» under «Вход в метро». Go write «To station» under «На станцию». Go write «All interchanges close at 1 past midnight» under «Переходы закрываются в 1 час ночи». Heck, go write transliterated names on the platforms themselves (and the ground terminals, of course). Even the newest stations’ architecture does not even leave a space for transliterated title.
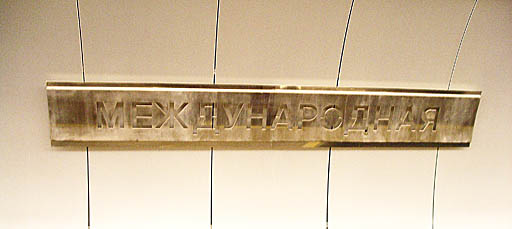
Международная, for sure. Transliterated map does not help much on this system.
Make the system friendlier, and then we’ll talk about putting English on the diagram.



{kind=link}
{kind=link}