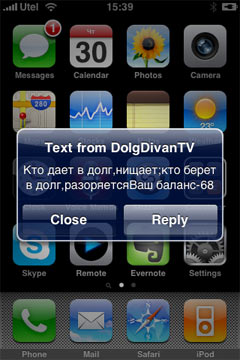
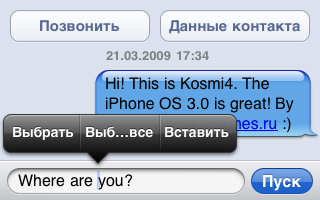
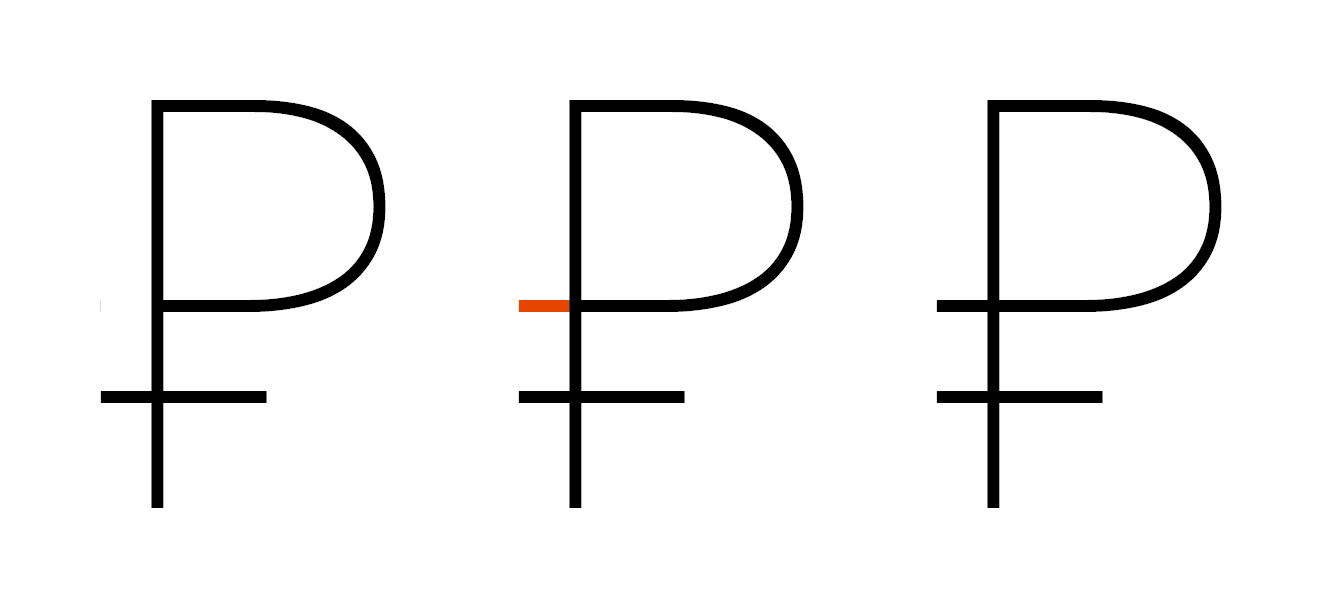У некоторых под Виндоусом Раскладка 2.0 вставляет лишние акуты при переключении языков. Я знаю об этом баге. Писать о самом факте его существования и в самом начале не было большого смысла, а сейчас его нет совсем.
У меня глюк происходит только в Фаерфоксе. Виндоус — Сервер 2003. Фаерфокс 3-й. Проявляется в том, что после переключения языка, хоть по Контроль+Шифту, хоть по Альт+Шифту, клавиатура попадает в режим слепой кнопки, печатающей всё с акутом, то есть всё ведёт себя так, будто после переключения языка Фаерфокс фиксирует нажатие Альт+Шифт+э и следующую кнопку интерпретирует уже с учётом него.
Есть ли люди, страдающие от этой проблемы в других программах? Пожалуйста, укажите полностью условия, в которых происходит баг; проверьте в вариантах переключения раскладок по Контроль+Шифту и Альт+Шифту.
Если глюк происходит только в Фаерфоксе, то, может быть, у кого-то из пользователей этого прекрасного браузера есть хотя бы гипотезы относительно того, почему это происходит? Возможно, есть какой-нибудь воркэраунд?
Если перевесить слепую кнопку акута с „э“ на прямой слеш, который под ней, баг у меня исчезает. Что из этого может следовать?
Заранее спасибо за помощь.
Обновление от 13 февраля 2009: Решение проблемы.