Тег: веб-разработка


В мае в Москве рассказал, как нормально делать адаптивные сайты
С техдиректором бюро Васей Половнёвым накидываем будущую лекцию «Основы информатики для дизайнеров»
В подкасте с Никитой Прокоповым мы всё время обсуждаем, как у Эпла всё деградирует, потому что все ресурсы направлены на новые маркетинговые фичи, а старые просто ржавеют

Участница подумала, что в дизайне хорошо бы сразу учесть закон о персональных данных. Я дополняю тем, что хорошо бы сразу учесть и требования сеошников
Вопрос спецам по Нгинксу
Дизайн «раскладок» для разных случаев, описание раскладок в коде, автоматический выбор и оценка раскладок, режим отладки
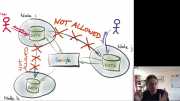
Как делать коллаборативные (они же мультиплеерные) приложения. Гугль-док, Фигма, OT, CRDT, все дела. Даёт хорошее представление о проблеме и решениях

Если из-за кеша вы видите устаревшие данные, значит в кеше баг